Let’s start a journey that brings your vision to life! 40 hours proof of concept for $2,500. Send your brief →

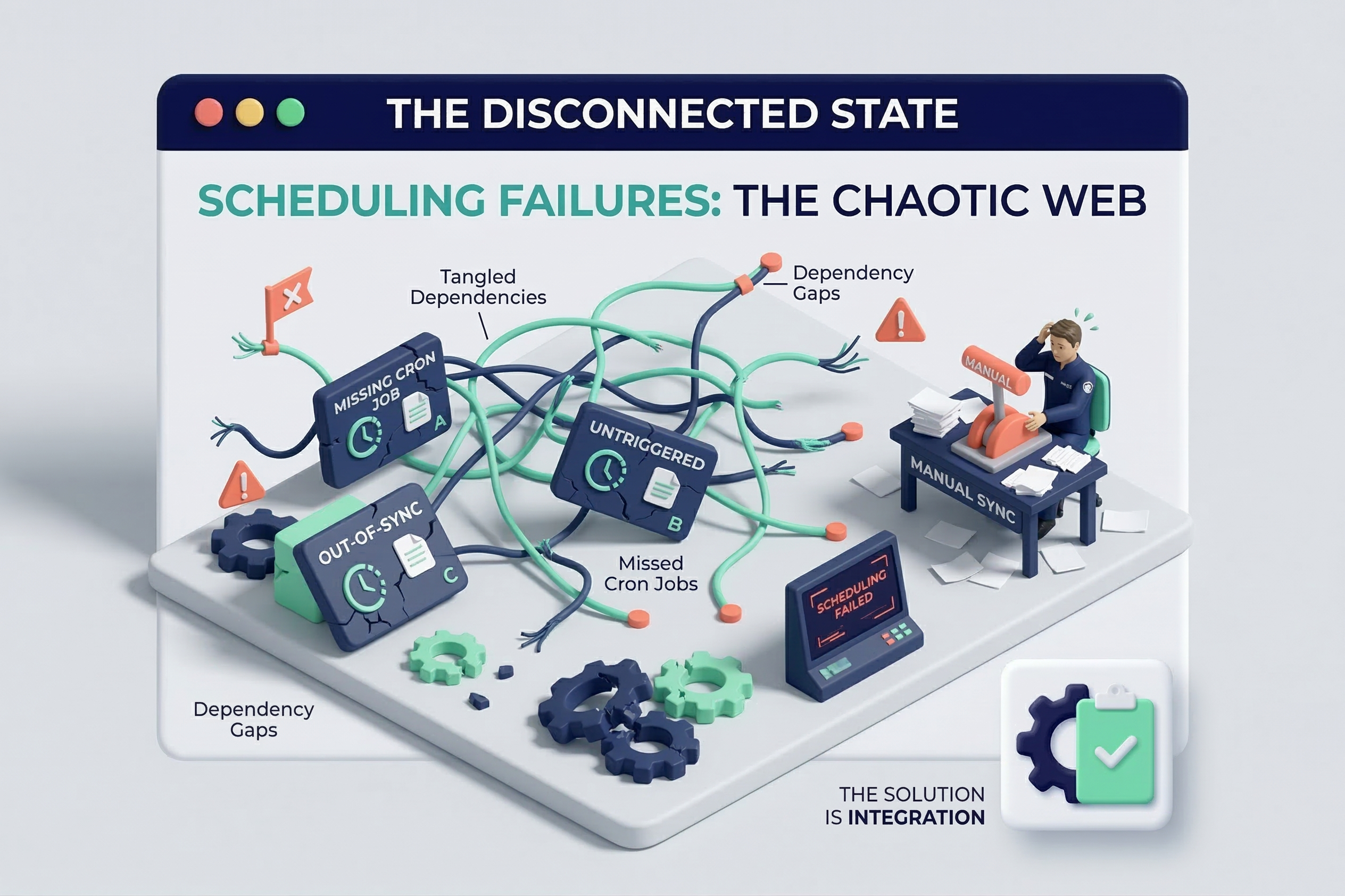
As data ecosystems grow, so does the complexity of managing them. What starts as a few automated scripts running on a schedule quickly spirals into a tangled web of dependencies. When a pipeline breaks, finding the root cause becomes a time-consuming forensic exercise, and silent failures can corrupt business dashboards before anyone notices.
To bring order, visibility, and reliability to our data infrastructure, our engineering team recently implemented a centralized orchestration layer using Apache Airflow. By treating our data pipelines as code, we transformed a fragile system into a robust, automated engine.
Here is a look at how we architected this solution.
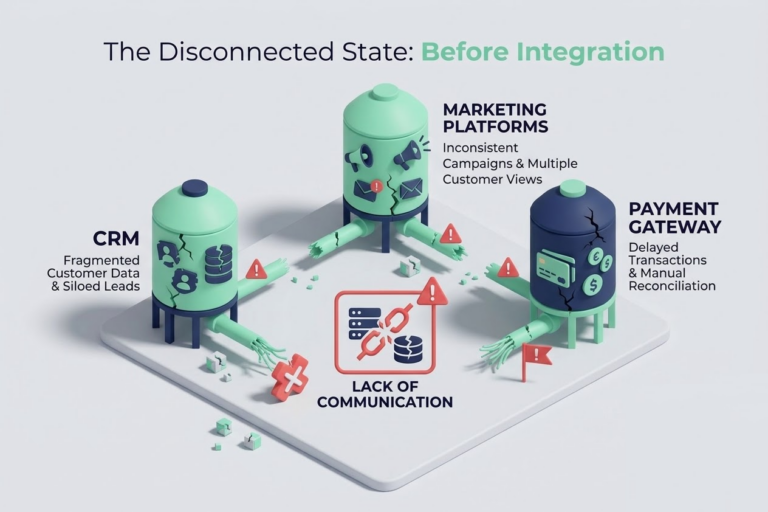
Prior to this project, data processes were scheduled independently. Extraction scripts, data warehouse loads, and transformation models were running on disconnected schedules without any awareness of each other.
The primary pain points included:
We needed a tool that could act as the “control room” for our entire data stack. We chose Apache Airflow because of its Python-based flexibility, dynamic DAG (Directed Acyclic Graph) generation, and rich ecosystem of operators that integrate seamlessly with our existing infrastructure (including modern tools like dbt, Docker, and cloud data warehouses).
Our team deployed a highly available Airflow environment to manage the end-to-end data lifecycle.
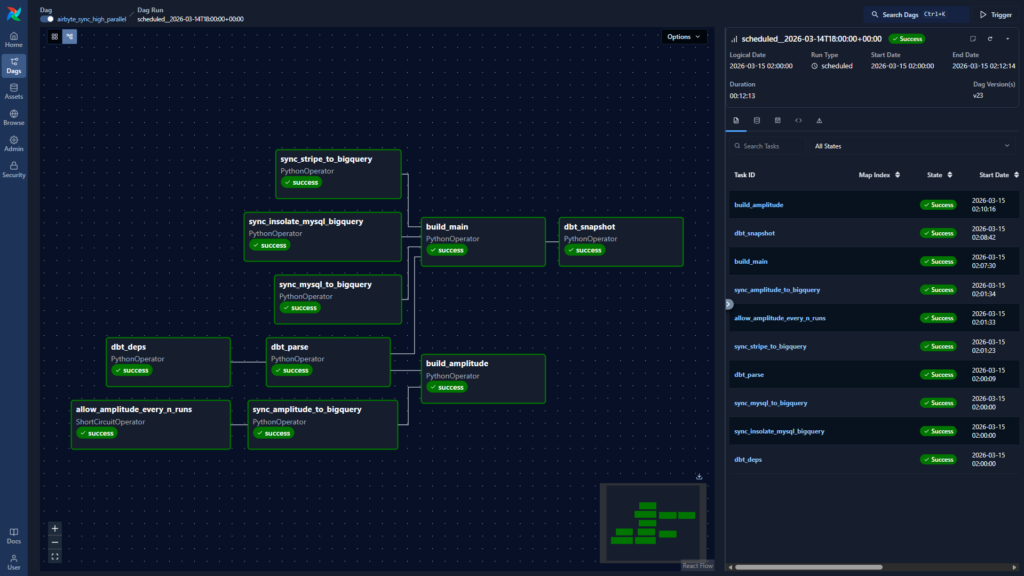
By migrating our data workflows to Airflow, we drastically reduced operational overhead and increased confidence in our data products.
Key project outcomes:
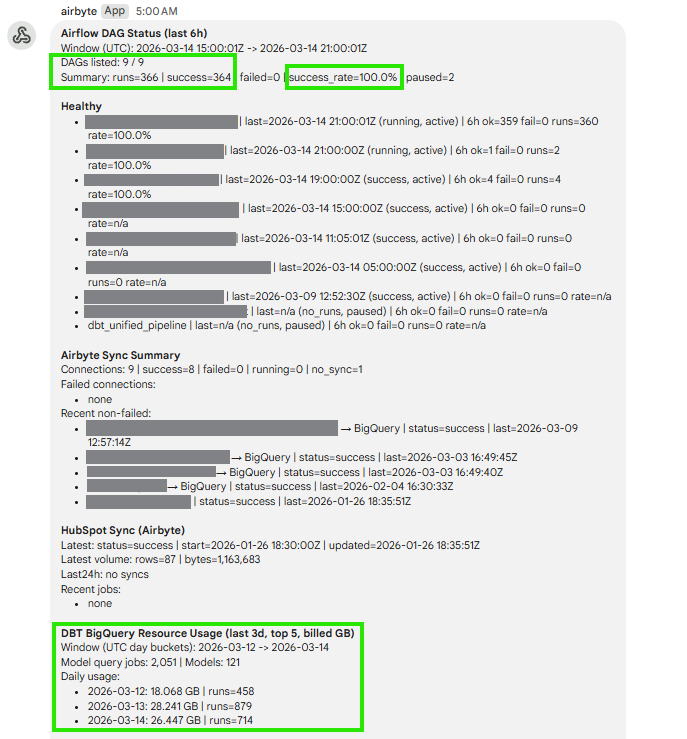
A modern data platform is only as reliable as the system orchestrating it. With Apache Airflow in place, our infrastructure is now scalable, resilient, and ready to handle exponentially more data without breaking a sweat.
If your data team is spending more time fixing broken pipelines than building new data products, it might be time to rethink your orchestration strategy. Reach out to us today to see how we can bring reliability to your data stack.