Let’s start a journey that brings your vision to life! 40 hours proof of concept for $2,500. Send your brief →


While massive, generalized Large Language Models (LLMs) dominate the market, they introduce high latency, token costs, and strict data privacy concerns for enterprise deployments. To address this, we engineered a custom, lightweight Natural Language Processing (NLP) engine from scratch. Built with Python, Keras, and TensorFlow, this specialized Chatbot utilizes Recurrent Neural Networks (RNNs) to deliver highly accurate, domain-specific customer service in both English and Spanish.
The Problem: The Overhead of Generalized AI
When a technology retailer needs to automate customer support, using a generic AI model is often overkill. These models are prone to hallucinations and require massive computational overhead to process simple, repetitive domain queries. Furthermore, mixing multiple languages in a single small-scale model often leads to context-bleeding and degraded response accuracy. The challenge was to build a system that is computationally efficient, strictly bounded to the company’s knowledge base, and capable of flawless bilingual interaction.
The Solution: Dual-LSTM Architectural Design
Instead of forcing one model to learn two languages, we implemented a decoupled architecture. The system intelligently detects the input language and routes the query to a dedicated, language-specific neural network.


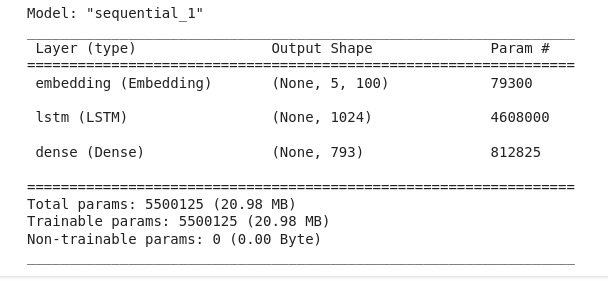



The Impact
This project proves that effective AI automation does not always require massive, third-party APIs. By engineering a custom, dual-LSTM architecture, we delivered a privacy-first, zero-hallucination customer service engine. It drastically reduces computational overhead while maintaining strict control over the corporate knowledge base and user data.
The Architecture Behind the Build Complex integrations require a clear vision. The underlying architecture and core development of Custom NLP Engine were spearheaded by our Solutions Architect, Israel Villaroel, ensuring the system wasn’t just intelligent, but built to scale and deploy seamlessly into real-world enterprise environments.