Let’s start a journey that brings your vision to life! 40 hours proof of concept for $2,500. Send your brief →

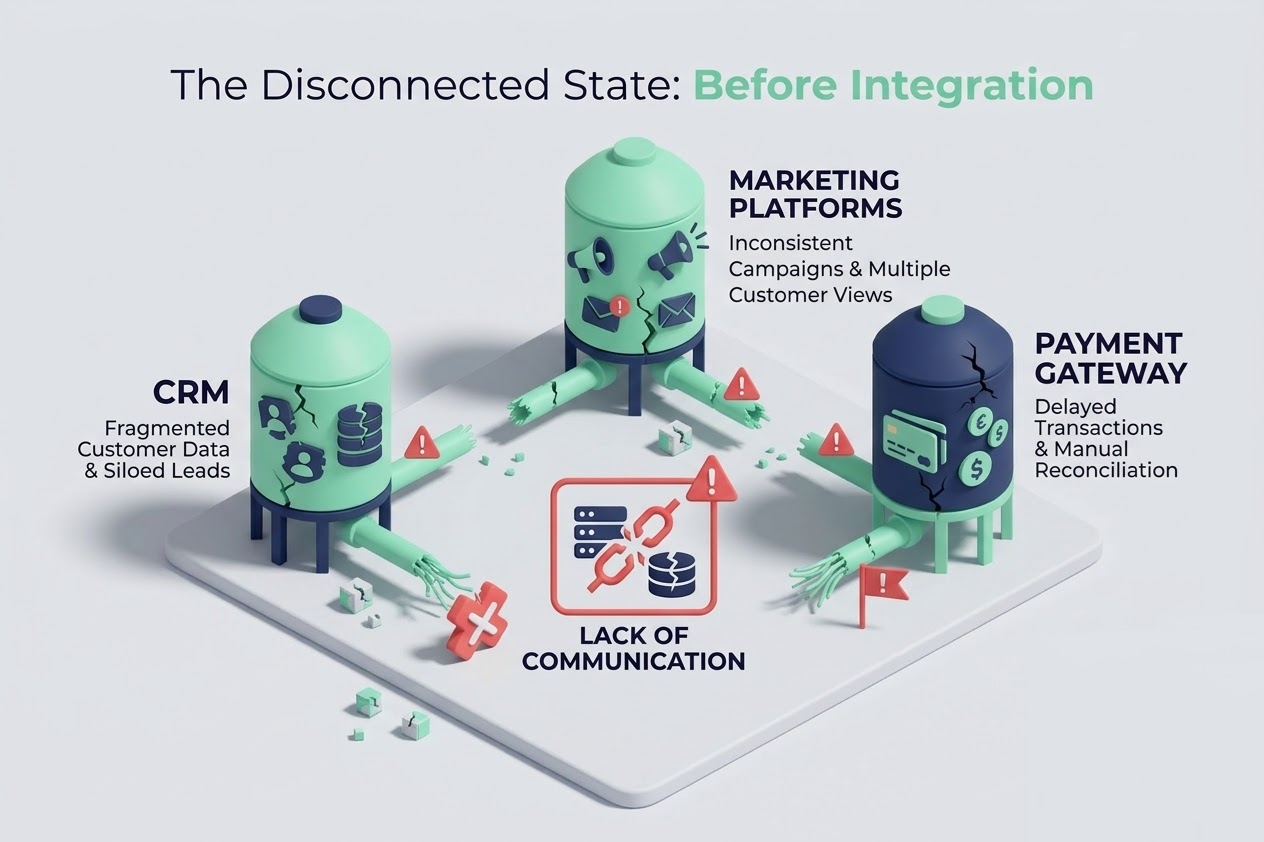
Every growing business eventually hits the same technical bottleneck: data silos. When your marketing metrics live in one platform, your transactional data in another, and your core application data in a fragmented database, gaining a holistic view of the company’s performance becomes a slow, manual nightmare.
Recently, our data engineering team tackled this exact challenge for a project, successfully architecting a highly scalable, automated data pipeline. By leveraging Airbyte, we synchronized multiple disparate data sources into a single, centralized Data Warehouse, transforming how the business interacts with its data.
Here is a look behind the scenes at how we built it.
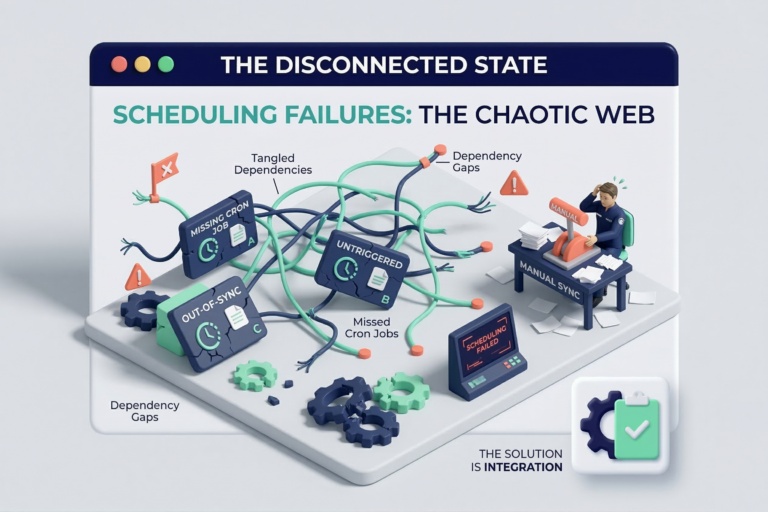
Before this implementation, the data landscape was scattered. Analytics and reporting required manual data extraction, complex Excel merges, and hours of engineering time just to answer basic operational questions.
The primary pain points included:
To solve this, we needed a robust ELT (Extract, Load, Transform) strategy. We chose Airbyte as our primary ingestion engine due to its extensive connector ecosystem, open-source flexibility, and reliable CDC (Change Data Capture) capabilities.
Our goal was simple: Automate the extraction of raw data from all third-party services and operational databases, and load it reliably into a scalable Cloud Data Warehouse.
Our team designed a streamlined architecture that prioritized automation and observability.
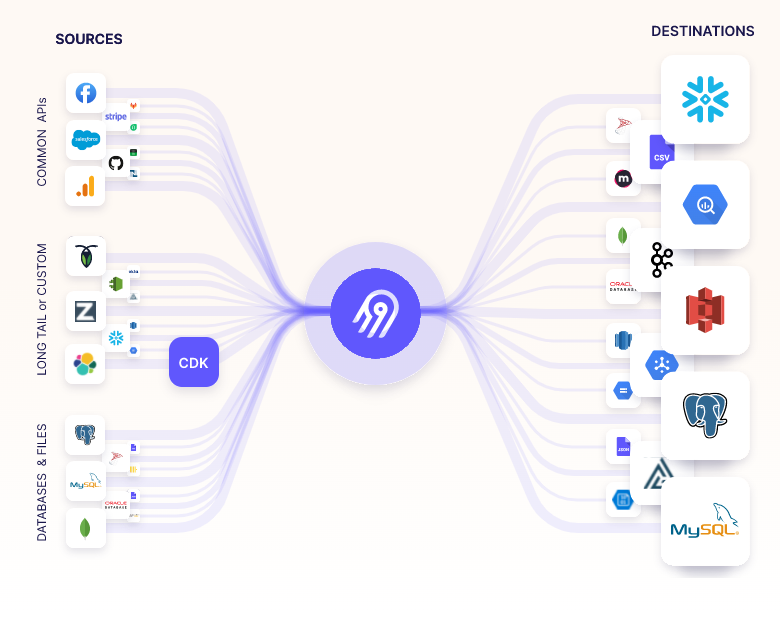
By implementing this Airbyte-driven pipeline, we replaced brittle, custom-coded integrations with a resilient, standardized infrastructure.
Key project outcomes:
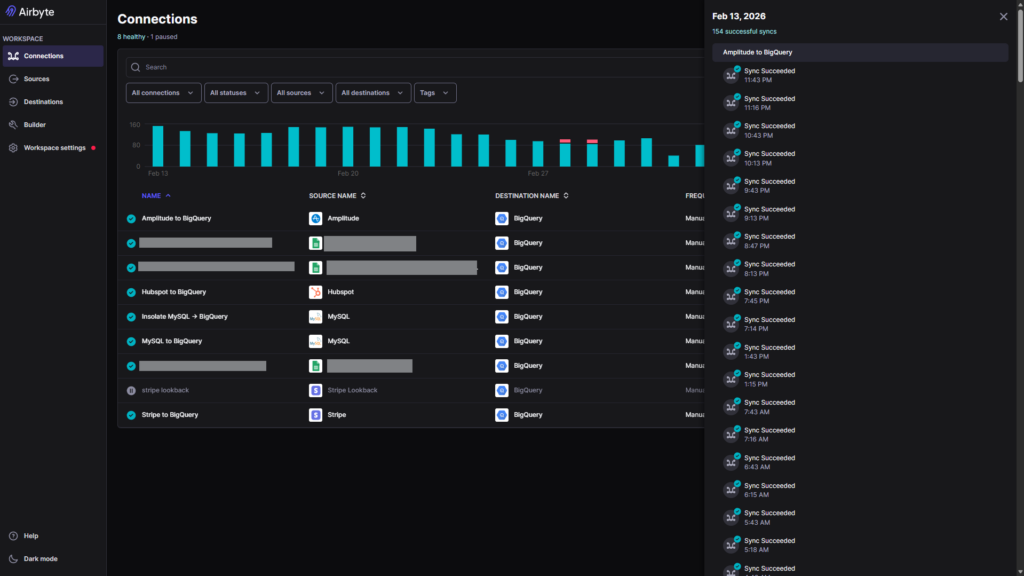
Centralizing your data is the foundational first step toward advanced analytics and machine learning. With a reliable, Airbyte-powered data warehouse now in place, the focus can shift from finding the data to actually using it to drive business value.
If your organization is struggling with data silos and manual reporting, our team has the expertise to architect a modern data stack tailored to your needs. Reach out to us today to discuss your next data project.