Let’s start a journey that brings your vision to life! 40 hours proof of concept for $2,500. Send your brief →

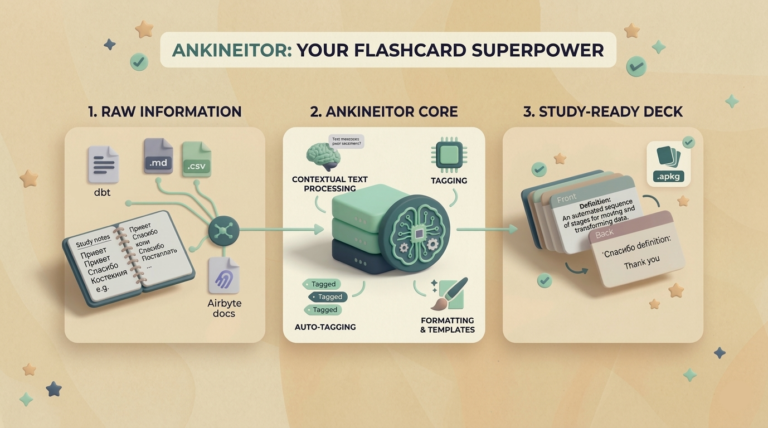
Information velocity within technical industries is a critical bottleneck. Staying competitive means ingesting, processing, and retaining vast amounts of data from divergent sources—including technical research papers (PDFs), engineering blogs (RSS feeds), and ad-hoc team updates (Telegram). Manual synthesis is too slow.
Our firm was tasked with developing a unified, intelligent system to ingest this information, normalize it, and apply sophisticated AI processing to generate structured knowledge assets (flashcards and summaries) automatically.
We selected n8n as the workflow orchestration engine for this project due to its flexibility in combining diverse APIs, robust conditional logic, and seamless integration with emerging LLM (Large Language Model) stacks.
Below is the complete architectural diagram of the solution we engineered. This complex, multi-layered workflow automates the entire knowledge management lifecycle, from raw data acquisition to structured storage and notification.
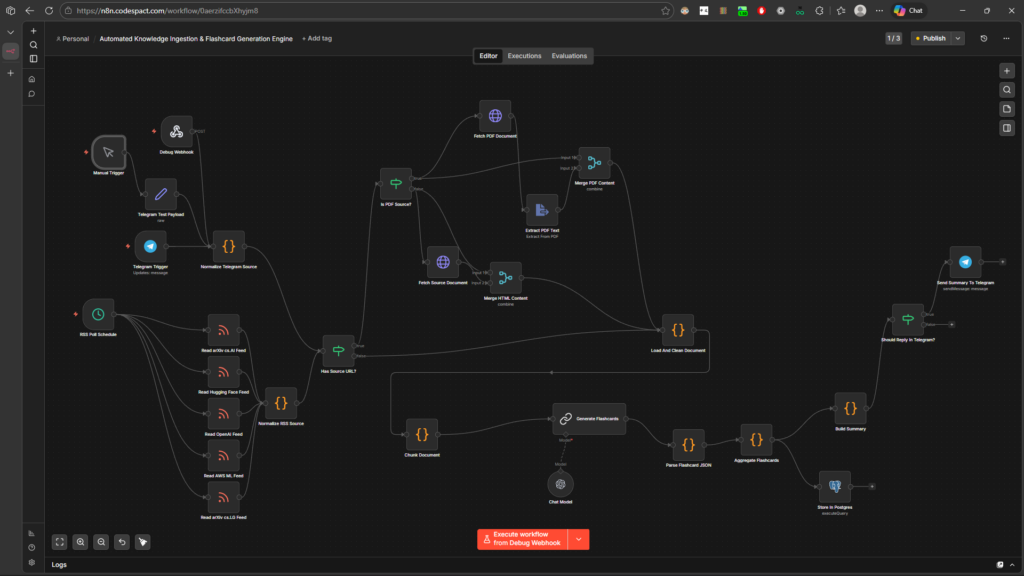
This workflow is structured into four main operational phases:
A robust pipeline must accept data on different schedules and from different contexts. We implemented multiple entry points:
A significant challenge in this project was data heterogeneity. A Telegram payload is structured differently than an RSS entry, and extracting text from a web article requires a different approach than extracting text from a complex scientific PDF. We implemented an ETL (Extract, Transform, Load) logic layer:
Has Source URL? -> Is PDF Source?).Fetch PDF Document and Extract PDF Text) to harvest the content, filtering out unnecessary metadata.Fetch Source Document and Extract Text Content).The core value proposition of this system is the intelligent synthesis of information. We didn’t just feed raw text into an LLM; we engineered a robust processing chain:
Chunk Document) and then cross-referenced against a vector store (Fetch Relevant Snippets). This ensures the AI model operates with precise context.Parse Flashcard JSON), ensuring it can be reliably used in downstream applications.The pipeline concludes by persisting the data and providing immediate value to the team:
Store in Postgres).Should Reply in Telegram?). If so, the bot immediately replies with the AI-generated summary and a count of the new flashcards generated, providing instant confirmation and synthesis to the user.This showcase piece demonstrates advanced proficiency in integrating disparate systems, handling heterogeneous data at scale, and implementing complex AI workflows beyond simple API calls. By moving from manual content consumption to an automated, RAG-enabled ETL process, we have built a system that turns the velocity of technical information from a challenge into a sustainable competitive advantage.