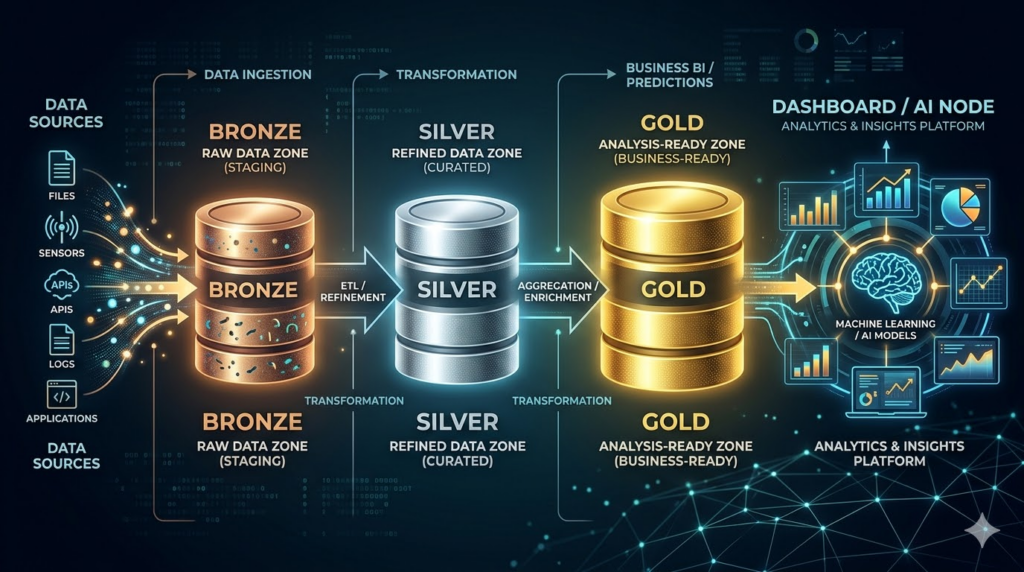
If you’re building data pipelines today, you know the chaos that ensues when raw data, business logic, and reporting views are all tangled together. Enter the Medallion Architecture—a data design pattern that brings order, scalability, and logical progression to your data lakehouse or warehouse.
Simply put, it’s a framework that organizes data into three distinct layers—Bronze, Silver, and Gold—progressively improving the structure and quality of the data as it moves through the pipeline. Here is a breakdown of how each layer functions in a modern data stack.
🥉 Bronze Layer: The Raw Data (Catch-All)
Think of the Bronze layer as the landing zone. This is where you ingest data from your external sources (APIs, transactional databases, third-party apps) in its raw, unprocessed format.
The Goal: Fast, reliable ingestion. We don’t worry about schema enforcement or deduplication here. We just want a historical archive of the data exactly as it arrived.
The Tech: This is where EL (Extract and Load) tools shine. Using a tool like Airbyte, you can seamlessly pull data from hundreds of sources and dump it directly into a Google Cloud Platform (GCP) storage bucket or BigQuery dataset, appending metadata like _load_timestamp.
🥈 Silver Layer: The Source of Truth (Cleaned & Validated)
The Silver layer is where the actual engineering happens. We take the messy Bronze data and clean, filter, and normalize it.
The Goal: Create an enterprise repository of clean, conformed data. We handle null values, deduplicate records, cast data types, and establish consistent naming conventions. This layer isn’t heavily aggregated yet; it still represents the granular entities of your business (e.g., customers, orders, events).
The Tech: This is the perfect territory for dbt (data build tool). By writing modular SQL, you can transform the raw Bronze tables into reliable Silver staging models, applying rigorous data tests along the way to ensure data quality
🥇 Gold Layer: The Business Value (Aggregated & Ready)
The Gold layer is built for consumption. Data here is highly refined, aggregated, and modeled specifically for business use cases, reporting, or advanced analytics.
The Goal: Deliver answers. This layer contains business-level entities and data marts (e.g., monthly_active_users, revenue_by_region). The schemas are optimized for read performance, often using star schemas (fact and dimension tables).
The Consumers: This is the data that feeds directly into BI dashboards, reporting tools, or serves as the foundational feature set for Artificial Intelligence and Machine Learning models.
Why Adopt the Medallion Architecture?
Reproducibility: If a transformation logic changes or a table gets corrupted in the Silver or Gold layers, you can simply drop it and rebuild it from the immutable Bronze layer.
Clear Data Governance: It restricts who can access what. Data scientists might need access to Silver for feature engineering, while business analysts only need the curated Gold tables.
Modularity: It separates concerns. If you change your ingestion tool, only the Bronze layer is affected. The downstream dbt models remain intact.
Building a robust data platform isn’t just about moving data from point A to point B; it’s about building trust in that data. The Medallion Architecture provides the structured framework needed to turn raw noise into valuable, actionable signals.
What does your system engineering and consulting involve?
Before writing code, we start with a deep technical diagnosis. We analyze your entire infrastructure, software, and daily operations to identify risks and real opportunities for system improvement.
Based on the initial diagnosis, we design a clear architecture and a realistic technical roadmap. Every single decision considers stability, scalability, and compatibility with your ongoing operations. We never apply generic fixes to complex tech systems.
Finally, we execute structural changes in a controlled and documented manner, strictly aligned with your internal teams. Execution is just a part of the process, not the end. We provide continuous tech support to ensure full platform adoption, smooth continuity, and the absolute capacity for future evolution.
Do you work with small businesses or only large companies?
We focus on the complexity of your systems rather than just the size of your company. We partner with organizations that already have running operations but face technical limits due to fast growth.
Often, companies scale their operations rapidly without establishing a solid technical architecture. They end up dealing with accumulated technical debt, unscalable software, or critical infrastructure that is simply too difficult and costly to maintain.
Whether you are a mid-sized team or a large enterprise, our tech interventions are always progressive and highly conscious. We deeply respect your ongoing processes and existing teams. Our main objective is to enable true technical evolution without ever putting your daily operational continuity at risk.
Can you update an existing platform?
Yes, we frequently intervene in existing platforms that suffer from accumulated technical debt.
Before any intervention, we completely analyze the entire system: your infrastructure, software, and processes. This allows us to spot operational risks and find the safest path to refactor your tech debts.
Our interventions are always progressive and highly conscious. We redesign the architecture and implement structural improvements without ever risking your daily operational continuity.
What technologies do you use for development?
We never rely on generic tools. Our tech stack is chosen based on your specific system needs. We utilize cloud infrastructure, robust software frameworks, and automated deployments to ensure solid stability.
We build robust backend architectures with Python and Laravel, and scalable applications using React Native. Our cloud infrastructure is strictly powered by Docker, Kubernetes, and GCP to ensure high availability.
For complex data and AI, we leverage TensorFlow and NLP models. Every tool is implemented with strict operational control and continuous support.
Do you provide support after launch?
Yes, we do. In codesPACT, execution is merely a part of the process, not the end. We provide continuous tech support to ensure your systems evolve with absolute stability, proper control, and a clear technical direction long after the initial deployment phases.
We accompany the transition to assure full adoption, continuity, and future evolution capacity. We do not just deliver the system; we make sure that your internal teams operate it securely.
This approach allows real improvements without generating unnecessary dependencies. Our ongoing role is to act as your technical partner for strategic decisions.
Newsletter subscribe!
Enter your email to unlock our exclusive IT insights on professional systems architecture tailored to your business needs.
Have tech questions?
Let’s schedule a short call to discuss how we can work together and contribute to the stability of your tech ecosystem.